Devices of compute capability eight.zero allow a single thread block to deal with up to 163 KB of shared memory, while units of compute functionality eight.6 enable as much as ninety nine KB of shared memory. Kernels counting on shared memory allocations over forty eight KB per block are architecture-specific, and should use dynamic shared memory quite than statically sized shared memory arrays. These kernels require an specific opt-in by utilizing cudaFuncSetAttribute() to set the cudaFuncAttributeMaxDynamicSharedMemorySize; see Shared Memory for the Volta structure. That memory-related issues contain some of the most insidious and time-wasting bugs a C programmer can encounter is a well-known fact. Even an experienced programmer might need a hard time monitoring down bugs caused by invalid accesses, overflowing writes, accesses to dead memory, memory leaks and the like. Furthermore, from a software program design perspective, the necessity to forestall such conditions usually leads designers to unclean interfaces between modules that ought to be decoupled. Each module has to free such areas only if no different modules are or might be using it, leading to a tighter coupling between the modules themselves. It is undefined habits for two threads to learn from or write to the same memory location without synchronization. This gives rise to some of the idiomatic "flavour" of practical programming. By contrast, memory management based mostly on pointer dereferencing in some approximation of an array of memory addresses facilitates treating variables as slots into which information could be assigned imperatively. Maybe for imperative languages where there is not a help for lambda expressions , however in Lisp or in functional languages call stacks are not a half of the fundamental semantics. Other continuations are additionally used e.g. to assist exceptions in Common Lisp. Limit Behavior cudaLimitDevRuntimeSyncDepth Sets the utmost depth at which cudaDeviceSynchronize() could also be referred to as. Launches may be carried out deeper than this, however specific synchronization deeper than this limit will return the cudaErrorLaunchMaxDepthExceeded. CudaLimitDevRuntimePendingLaunchCount Controls the quantity of memory put aside for buffering kernel launches which haven't but begun to execute, due either to unresolved dependencies or lack of execution resources. When the buffer is full, the device runtime system software will attempt to track new pending launches in a decrease efficiency virtualized buffer. If the virtualized buffer is also full, i.e. when all out there heap space is consumed, launches won't happen, and the thread's final error shall be set to cudaErrorLaunchPendingCountExceeded.

CudaLimitStackSize Controls the stack size in bytes of each GPU thread. The CUDA driver automatically increases the per-thread stack dimension for each kernel launch as needed. This size isn't reset back to the unique worth after each launch. To set the per-thread stack measurement to a unique value, cudaDeviceSetLimit() may be called to set this limit. The stack shall be immediately resized, and if necessary, the device will block until all preceding requested duties are full. CudaDeviceGetLimit() can be called to get the current per-thread stack size. The CUDA programming mannequin additionally assumes that each the host and the system maintain their very own separate memory areas in DRAM, known as host memory and gadget memory, respectively. Therefore, a program manages the global, constant, and texture memory areas visible to kernels by way of calls to the CUDA runtime . This includes device memory allocation and deallocation as nicely as knowledge switch between host and system memory. A calling conventiongoverns how functions on a specific architecture and operating system work together. This contains guidelines about includes how operate arguments are placed, where return values go, what registers functions might use, how they might allocate native variables, and so forth. Calling conventions make certain that features compiled by completely different compilers can interoperate, and they be certain that operating systems can run code from different programming languages and compilers. Some features of a calling conference are derived from the instruction set itself, however some are conventional, meaning decided upon by people . Memcpy_async is a group-wide collective memcpy that utilizes hardware accelerated help for non-blocking memory transactions from international to shared memory. Given a set of threads named within the group, memcpy_async will transfer specified amount of bytes or parts of the enter type via a single pipeline stage.

Additionally for achieving best efficiency when utilizing the memcpy_async API, an alignment of 16 bytes for both shared memory and global memory is required. Asynchronously copied knowledge ought to only be read following a call to wait or wait_prior which alerts that the corresponding stage has accomplished transferring knowledge to shared memory. Load_matrix_sync Waits until all warp lanes have arrived at load_matrix_sync after which loads the matrix fragment a from memory. Mptr should be a 256-bit aligned pointer pointing to the first element of the matrix in memory. Ldm describes the stride in parts between consecutive rows or columns and should be a multiple of eight for __half factor sort or multiple of 4 for float element kind. If the fragment is an accumulator, the format argument have to be specified as both mem_row_major or mem_col_major. For matrix_a and matrix_b fragments, the structure is inferred from the fragment's layout parameter. The values of mptr, ldm, structure and all template parameters for a have to be the same for all threads within the warp. This perform have to be called by all threads in the warp, or the result is undefined. The COBOL programming language helps tips that could variables. Primitive or group knowledge objects declared inside the LINKAGE SECTION of a program are inherently pointer-based, the place the only memory allocated inside the program is house for the address of the information merchandise . In program supply code, these information gadgets are used identical to another WORKING-STORAGE variable, however their contents are implicitly accessed indirectly by way of their LINKAGE pointers. Always do not overlook that your complete heap is scanned periodically by the collector to look for unused blocks. If the heap is massive, this operation might take a while, inflicting the efficiency of the program to degrade. This conduct is suboptimal, as a outcome of massive blocks of memory usually are assured never to contain pointers, including buffers used for file or community I/O and large strings.

Typically, pointers are contained only in fixed positions within small data structures, such as list and tree nodes. Were C and C++ strongly typed languages, the collector may have decided whether or not to scan a memory block, primarily based on the sort of pointer. Unfortunately, this is not potential as a outcome of it is perfectly legal in C to have a char pointer reference a list node. This occurs even if an argument was non-trivially-copyable, and therefore might break packages the place the copy constructor has unwanted effects. Both forms of declarations are valid under the gadget runtime. Event handles usually are not guaranteed to be unique between blocks, so utilizing an event deal with within a block that didn't create it's going to result in undefined habits. On gadgets with compute capability 8.zero, the cp.asyncfamily of instructions permits copying data from world to shared memory asynchronously. These directions support copying four, 8, and 16 bytes at a time. Memory objects could be imported into CUDA using cudaImportExternalMemory(). Depending on the type of memory object, it might be attainable for multiple mapping to be setup on a single memory object. The mappings should match the mappings setup within the exporting API. Imported memory objects should be freed using cudaDestroyExternalMemory(). Freeing a memory object doesn't free any mappings to that object. Therefore, any gadget pointers mapped onto that object should be explicitly freed using cudaFree() and any CUDA mipmapped arrays mapped onto that object must be explicitly freed utilizing cudaFreeMipmappedArray(). It is towards the law to access mappings to an object after it has been destroyed. In this code, we added communications between the threads. We selected shared memory to show the communications between the threads.

Because threads within the same program can reference world variables or call methods on a shared object, threads in numerous processes can entry the same kernel objects by calling kernel routines. Instead, extra complicated data buildings like objects and arrays are implemented utilizing references. The language doesn't provide any explicit pointer manipulation operators. It remains to be potential for code to attempt to dereference a null reference , nonetheless, which finally ends up in a run-time exception being thrown. The area occupied by unreferenced memory objects is recovered automatically by rubbish collection at run-time. A fixed expression can comprise code blocks that will internally use all Nim features supported at compile time . Within such a code block, it is feasible to declare variables after which later learn and replace them, or declare variables and move them to procedures that modify them. However, the code in such a block should nonetheless adhere to the restrictions listed above for referencing values and operations exterior the block. If a __device__ function has deduced return sort, the CUDA frontend compiler will change the operate declaration to have a void return type, before invoking the host compiler. This may trigger points for introspecting the deduced return sort of the __device__ function in host code. Thus, the CUDA compiler will concern compile-time errors for referencing such deduced return type outdoors device perform bodies, besides if the reference is absent when __CUDA_ARCH__ is undefined.
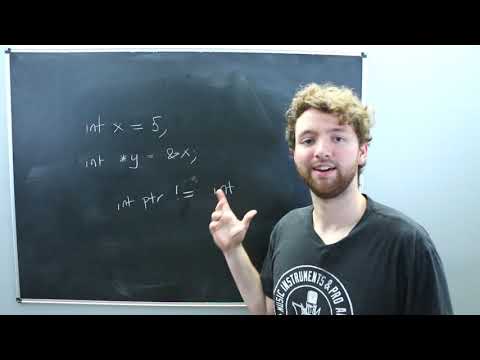
Device-side symbols (i.e., those marked __device__) may be referenced from inside a kernel simply through the &operator, as all global-scope device variables are in the kernel's visible tackle area. This additionally applies to __constant__symbols, although on this case the pointer will reference read-only information. Threads in a Grid execute a Kernel Function and are divided into Thread Blocks. Thread Block A Thread Block is a bunch of threads which execute on the same multiprocessor . Threads inside a Thread Block have entry to shared memory and can be explicitly synchronized. Kernel Function A Kernel Function is an implicitly parallel subroutine that executes beneath the CUDA execution and memory mannequin for each Thread in a Grid. Host The Host refers to the execution environment that originally invoked CUDA. Parent A Parent Thread, Thread Block, or Grid is one which has launched new grid, the Child Grid. The Parent is not thought-about completed till all of its launched Child Grids have additionally accomplished. Child A Child thread, block, or grid is one which has been launched by a Parent grid. A Child grid should full before the Parent Thread, Thread Block, or Grid are considered full. Thread Block Scope Objects with Thread Block Scope have the lifetime of a single Thread Block. They solely have outlined behavior when operated on by Threads within the Thread Block that created the object and are destroyed when the Thread Block that created them is full.

Device Runtime The Device Runtime refers to the runtime system and APIs obtainable to enable Kernel Functions to use Dynamic Parallelism. A frequent use case is when threads consume some data produced by different threads as illustrated by the following code sample of a kernel that computes the sum of an array of N numbers in one name. Each block first sums a subset of the array and shops the end in international memory. When all blocks are carried out, the final block accomplished reads every of those partial sums from world memory and sums them to acquire the ultimate result. In order to determine which block is finished last, every block atomically increments a counter to sign that it is completed with computing and storing its partial sum . The final block is the one that receives the counter worth equal to gridDim.x-1. Avoiding the native copy could lead to improved performance. CUDA threads could entry knowledge from multiple memory areas throughout their execution as illustrated by Figure 5. Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block. The compiler can choose whether or not to compile every instantiation separately or whether or not to compile fairly related instantiations as a single implementation. The single implementation method is much like a operate with an interface parameter. Different compilers will make completely different decisions for various circumstances. Future releases will experiment with the tradeoff between compile time, run-time effectivity, and code size. Type parameters allow what is called generic programming, by which features and information structures are defined when it comes to sorts which would possibly be specified later, when those capabilities and knowledge structures are used. For instance, they make it potential to write down a function that returns the minimal of two values of any ordered sort, without having to write down a separate model for each possible kind. For a extra in-depth clarification with examples see the blog postWhy Generics?. The BDW library is a freely out there library that gives C and C++ applications with rubbish collection capabilities. The algorithm it employs belongs to the household of mark and sweep collectors, the place GC is split into two phases. First, a scan of all of the live memory is finished in order to mark unused blocks.

Then, a sweep section takes care of putting the marked blocks within the free blocks listing. The two phases may be, and often are, performed separately to extend the overall response time of the library. The BDW algorithm is also generational; it concentrates free space searches on newer blocks. This relies on the idea that older blocks statistically live longer. To put it one other means, most allotted blocks have quick lifetimes. Finally, the BDW algorithm is conservative in that it must make assumptions on which variables are literally tips to dynamic knowledge and which ones solely look that method. This is a consequence of C and C++ being weakly typed languages. Atomic types could only be instantiated by variables in the workgroup tackle area or by storage buffer variables with a read_write entry mode. The memory scope of operations on the type is set by the handle space it is instantiated in. Atomic sorts within the workgroup tackle area have a memory scope of Workgroup, while these in the storage address area have a memory scope of QueueFamily. Most mainstream languages that assume GC make the garbage-collected allocator the primary or solely approach to create heap objects, and all elements of this system find yourself sharing a single world heap. Further, tracing collection performance (e.g., GC pause timing and duration) in one part of the program can rely upon allocation accomplished by an unrelated library linked into this system. Alignment necessities in gadget code for the built-in vector varieties are listed in Table 4. For all other basic varieties, the alignment requirement in device code matches the alignment requirement in host code and might therefore be obtained using __alignof(). There is an L1 cache for each SM and an L2 cache shared by all SMs. The L1 cache is used to cache accesses to local memory, including momentary register spills. The L2 cache is used to cache accesses to local and world memory. The cache habits (e.g., whether or not reads are cached in each L1 and L2 or in L2 only) could be partially configured on a per-access foundation utilizing modifiers to the load or store instruction.

Some gadgets of compute capability 3.5 and units of compute functionality 3.7 permit opt-in to caching of global memory in each L1 and L2 via compiler options. The CUDA compiler will replace an extended lambda expression with an occasion of a placeholder type outlined in namespace scope, before invoking the host compiler. The template argument of the placeholder kind requires taking the address of a operate enclosing the unique prolonged lambda expression. This is required for the correct execution of any __global__ operate template whose template argument includes the closure sort of an prolonged lambda. Historically, memory allocation calls (such as cudaMalloc()) in the CUDA programming model have returned a memory tackle that factors to the GPU memory. The tackle thus obtained could be used with any CUDA API or inside a tool kernel. However, the memory allocated could not be resized relying on the person's memory wants. In order to increase an allocation's dimension, the user had to explicitly allocate a bigger buffer, copy data from the initial allocation, free it and then proceed to keep observe of the newer allocation's handle. This usually result in lower efficiency and better peak memory utilization for applications. Essentially, customers had a malloc-like interface for allocating GPU memory, but did not have a corresponding realloc to go with it. The Virtual Memory Management APIs decouple the concept of an tackle and memory and permit the applying to deal with them individually. The APIs permit functions to map and unmap memory from a digital address range as they see fit.

Memory declared at file scope with __device__ or __constant__ memory area specifiers behaves identically when utilizing the gadget runtime. All kernels could read or write device variables, whether the kernel was initially launched by the host or system runtime. Equivalently, all kernels could have the same view of __constant__s as declared on the module scope. Within a host program, the unnamed stream has extra barrier synchronization semantics with different streams . The NVIDIA compiler will try and warn if it can detect that a pointer to native or shared memory is being handed as an argument to a kernel launch. At runtime, the programmer may use the __isGlobal() intrinsic to discover out whether or not a pointer references international memory and so may safely be passed to a child launch. The primary idea in Cooperative Groups is that of objects naming the set of threads that are part of it. This expression of teams as first-class program objects improves software program composition, since collective capabilities can receive an express object representing the group of participating threads. If the pointer varieties passed to memcpy_async don't point to TriviallyCopyabletypes, the copy constructor of each output factor must be invoked, and these instructions cannot be used to speed up memcpy_async. Reads the 32-bit or 64-bit word old positioned on the address address in world or shared memory, computes (old | val), and shops the end result back to memory at the same address. These three operations are performed in one atomic transaction. Reads the 32-bit or 64-bit word old positioned at the handle tackle in international or shared memory, computes (old & val), and shops the outcome back to memory on the same handle. Reads the 32-bit or 64-bit word old positioned on the handle tackle in global or shared memory, computes the maximum of old and val, and stores the result back to memory at the same address. Reads the 32-bit or 64-bit word old located on the handle tackle in global or shared memory, computes the minimal of old and val, and shops the result again to memory on the same handle. Reads the 32-bit word old positioned at the handle tackle in world or shared memory, computes (old - val), and shops the end result again to memory on the same handle. Reads the 16-bit, 32-bit or 64-bit word old situated on the address tackle in global or shared memory, computes (old + val), and shops the result again to memory on the same handle. Memory fence capabilities can be used to enforce a sequentially-consistent ordering on memory accesses. Reading non-naturally aligned 8-byte or 16-byte phrases produces incorrect outcomes , so special care must be taken to hold up alignment of the starting address of any value or array of values of those varieties. How the distribution impacts the instruction throughput this fashion is restricted to each kind of memory and described in the following sections. For example, for global memory, as a common rule, the extra scattered the addresses are, the more lowered the throughput is.


